
Docker is a software platform for building applications based on containers — small and lightweight execution environments that make shared use of the operating system kernel but otherwise run in isolation from one another. While containers as a concept have been around for some time, Docker, an open source project launched in 2013, helped popularize the technology, and has helped drive the trend towards containerization and microservices in software development that has come to be known as cloud-native development.
What are containers?
One of the goals of modern software development is to keep applications on the same host or cluster isolated from one another so they don’t unduly interfere with each other’s operation or maintenance. This can be difficult, thanks to the packages, libraries, and other software components required for them to run. One solution to this problem has been virtual machines, which keep applications on the same hardware entirely separate, and reduce conflicts among software components and competition for hardware resources to a minimum. But virtual machines are bulky—each requires its own OS, so is typically gigabytes in size—and difficult to maintain and upgrade.
Containers, by contrast, isolate applications’ execution environments from one another, but share the underlying OS kernel. They’re typically measured in megabytes, use far fewer resources than VMs, and start up almost immediately. They can be packed far more densely on the same hardware and spun up and down en masse with far less effort and overhead. Containers provide a highly efficient and highly granular mechanism for combining software components into the kinds of application and service stacks needed in a modern enterprise, and for keeping those software components updated and maintained.
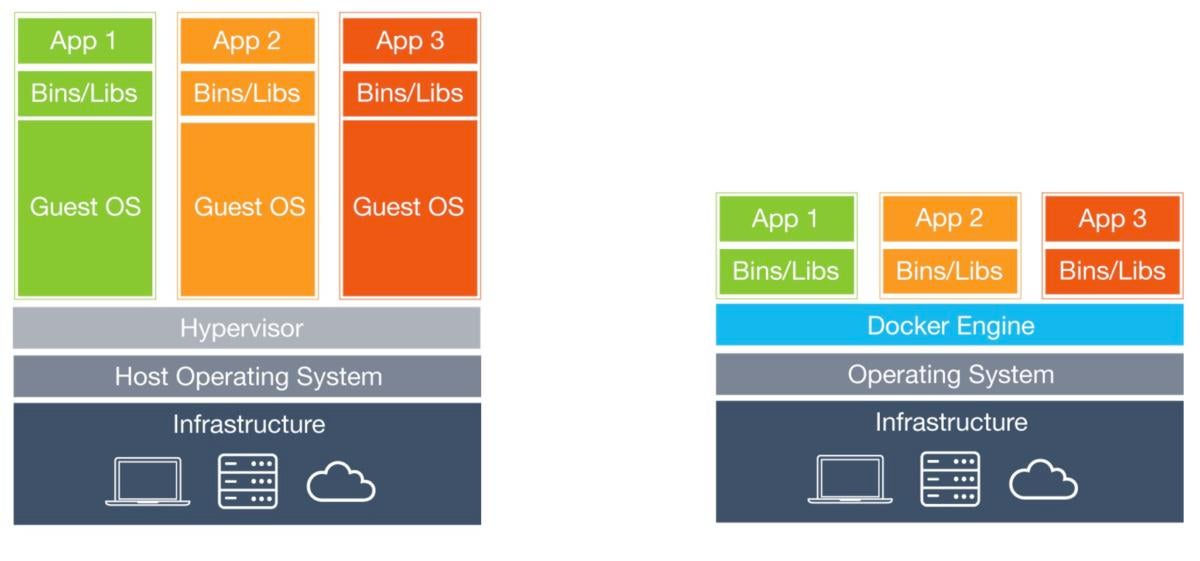 Docker
DockerHow the virtualization and container infrastructure stacks stack up.
What is Docker?
Docker is an open source project that makes it easy to create containers and container-based apps. Originally built for Linux, Docker now runs on Windows and MacOS as well. To understand how Docker works, let’s take a look at some of the components you would use to create Docker-containerized applications.
Dockerfile
Each Docker container starts with a Dockerfile. A Dockerfile is a text file written in an easy-to-understand syntax that includes the instructions to build a Docker image (more on that in a moment). A Dockerfile specifies the operating system that will underlie the container, along with the languages, environmental variables, file locations, network ports, and other components it needs—and, of course, what the container will actually be doing once we run it.
Paige Niedringhaus over at ITNext has a good breakdown of the syntax of a Dockerfile.
Docker image
Once you have your Dockerfile written, you invoke the Docker build utility to create an image based on that Dockerfile. Whereas the Dockerfile is the set of instructions that tells build how to make the image, a Docker image is a portable file containing the specifications for which software components the container will run and how. Because a Dockerfile will probably include instructions about grabbing some software packages from online repositories, you should take care to explicitly specify the proper versions, or else your Dockerfile might produce inconsistent images depending on when it’s invoked. But once an image is created, it’s static. Codefresh offers a look at how to build an image in more detail.
Docker run
Docker’s run utility is the command that actually launches a container. Each container is an instance of an image. Containers are designed to be transient and temporary, but they can be stopped and restarted, which launches the container into the same state as when it was stopped. Further, multiple container instances of the same image can be run simultaneously (as long as each container has a unique name). The Code Review has a great breakdown of the different options for the run command, to give you a feel for how it works.
Docker Hub
While building containers is easy, don’t get the idea that you’ll need to build each and every one of your images from scratch. Docker Hub is a SaaS repository for sharing and managing containers, where you will find official Docker images from open-source projects and software vendors and unofficial images from the general public. You can download container images containing useful code, or upload your own, share them openly, or make them private instead. You can also create a local Docker registry if you prefer. (Docker Hub has had problems in the past with images that were uploaded with backdoors built into them.)
Docker Engine
Docker Engine is the core of Docker, the underlying client-server technology that creates and runs the containers. Generally speaking, when someone says Docker generically and isn’t talking about the company or the overall project, they mean Docker Engine. There are two different versions of Docker Engine on offer: Docker Engine Enterprise and Docker Engine Community.
Docker Community Edition
Docker released its Enterprise Edition in 2017, but its original offering, renamed Docker Community Edition, remains open source and free of charge, and did not lose any features in the process. Instead, Enterprise Edition, which costs $1,500 per node per year, added advanced management features including controls for cluster and image management, and vulnerability monitoring. The BoxBoat blog has a rundown of the differences between the editions.
How Docker conquered the container world
The idea that a given process can be run with some degree of isolation from the rest of its operating environment has been built into Unix operating systems such as BSD and Solaris for decades. The original Linux container technology, LXC, is an OS-level virtualization method for running multiple isolated Linux systems on a single host. LXC was made possible by two Linux features: namespaces, which wrap a set of system resources and present them to a process to make it look like they are dedicated to that process; and cgroups, which govern the isolation and usage of system resources, such as CPU and memory, for a group of processes.
Containers decouple applications from operating systems, which means that users can have a clean and minimal Linux operating system and run everything else in one or more isolated container. And because the operating system is abstracted away from containers, you can move a container across any Linux server that supports the container runtime environment.
Docker introduced several significant changes to LXC that make containers more portable and flexible to use. Using Docker containers, you can deploy, replicate, move, and back up a workload even more quickly and easily than you can do so using virtual machines. Docker brings cloud-like flexibility to any infrastructure capable of running containers. Docker’s container image tools were also an advance over LXC, allowing a developer to build libraries of images, compose applications from multiple images, and launch those containers and applications on local or remote infrastructure.
Docker Compose, Docker Swarm, and Kubernetes
Docker also makes it easier to coordinate behaviors between containers, and thus build application stacks by hitching containers together. Docker Compose was created by Docker to simplify the process of developing and testing multi-container applications. It’s a command-line tool, reminiscent of the Docker client, that takes in a specially formatted descriptor file to assemble applications out of multiple containers and run them in concert on a single host. (Check out InfoWorld’s Docker Compose tutorial to learn more.)
More advanced versions of these behaviors—what’s called container orchestration—are offered by other products, such as Docker Swarm and Kubernetes. But Docker provides the basics. Even though Swarm grew out of the Docker project, Kubernetes has become the de facto Docker orchestration platform of choice.
Docker advantages
Docker containers provide a way to build enterprise and line-of-business applications that are easier to assemble, maintain, and move around than their conventional counterparts.
Docker containers enable isolation and throttling
Docker containers keep apps isolated not only from each other, but from the underlying system. This not only makes for a cleaner software stack, but makes it easier to dictate how a given containerized application uses system resources—CPU, GPU, memory, I/O, networking, and so on. It also makes it easier to ensure that data and code are kept separate. (See “Docker containers are stateless and immutable,” below.)
Docker containers enable portability
A Docker container runs on any machine that supports the container’s runtime environment. Applications don’t have to be tied to the host operating system, so both the application environment and the underlying operating environment can be kept clean and minimal.
For instance, a MySQL for Linux container will run on most any Linux system that supports containers. All of the dependencies for the app are typically delivered in the same container.
Container-based apps can be moved easily from on-prem systems to cloud environments or from developers’ laptops to servers, as long as the target system supports Docker and any of the third-party tools that might be in use with it, such as Kubernetes (see “Docker containers ease orchestration and scaling,” below).
Normally, Docker container images must be built for a specific platform. A Windows container, for instance, will not run on Linux and vice versa. Previously, one way around this limitation was to launch a virtual machine that ran an instance of the needed operating system, and run the container in the virtual machine.
However, the Docker team has since devised a more elegant solution, called manifests, which allow images for multiple operating systems to be packed side-by-side in the same image. Manifests are still considered experimental, but they hint at how containers might become a cross-platform application solution as well as a cross-environment one.
Docker containers enable composability
Most business applications consist of several separate components organized into a stack—a web server, a database, an in-memory cache. Containers make it possible to compose these pieces into a functional unit with easily changeable parts. Each piece is provided by a different container and can be maintained, updated, swapped out, and modified independently of the others.
This is essentially the microservices model of application design. By dividing application functionality into separate, self-contained services, the microservices model offers an antidote to slow traditional development processes and inflexible monolithic apps. Lightweight and portable containers make it easier to build and maintain microservices-based applications.
Docker containers ease orchestration and scaling
Because containers are lightweight and impose little overhead, it’s possible to launch many more of them on a given system. But containers can also be used to scale an application across clusters of systems, and to ramp services up or down to meet spikes in demand or to conserve resources.
The most enterprise-grade versions of the tools for deployment, managing, and scaling containers are provided by way of third-party projects. Chief among them is Google’s Kubernetes, a system for automating how containers are deployed and scaled, but also how they’re connected together, load-balanced, and managed. Kubernetes also provides ways to create and re-use multi-container application definitions or “Helm charts,” so that complex app stacks can be built and managed on demand.
Docker also includes its own built-in orchestration system, Swarm mode, which is still used for cases that are less demanding. That said, Kubernetes has become something of the default choice; in fact, Kubernetes is bundled with Docker Enterprise Edition.
Docker caveats
Containers solve a great many problems, but they aren’t cure-alls. Some of their shortcomings are by design, while others are byproducts of their design.
Docker containers are not virtual machines
The most common conceptual mistake people make with containers is to equate them with virtual machines. However, because containers and virtual machines use different isolation mechanisms, they have distinctly different advantages and disadvantages.
Virtual machines provide a high degree of isolation for processes, since they run in their own instance of an operating system. That operating system doesn’t have to be the same as the one run on the host, either. A Windows virtual machine can run on a Linux hypervisor and vice versa.
Containers, by contrast, use controlled portions of the host operating system’s resources; many applications share the same OS kernel, in a highly managed way. As a result, containerized apps aren’t as thoroughly isolated as virtual machines, but they provide enough isolation for the vast majority of workloads.
Docker containers don’t provide bare-metal speed

Containers don’t have nearly the overhead of virtual machines, but their performance impact is still measurable. If you have a workload that requires bare-metal speed, a container might be able to get you close enough—much closer than a VM—but you’re still going to see some overhead.
Docker containers are stateless and immutable
Containers boot and run from an image that describes their contents. That image is immutable by default—once created, it doesn’t change.
Consequently, containers don’t have persistency. If you start a container instance, then kill it and restart it, the new container instance won’t have any of the stateful information associated with the old one.
This is another way containers differ from virtual machines. A virtual machine has persistency across sessions by default, because it has its own file system. With a container, the only thing that persists is the image used to boot the software that runs in the container; the only way to change that is to create a new, revised container image.
On the plus side, the statelessness of containers makes the contents of containers more consistent, and easier to compose predictably into application stacks. It also forces developers to keep application data separate from application code.
If you want a container to have any kind of persistent state, you need to place that state somewhere else. That could be a database or a stand-alone data volume connected to the container at boot time.
Docker containers are not microservices
I mentioned earlier how containers lend themselves to creating microservices applications. That doesn’t mean taking a given application and sticking it into a container will automatically create a microservice. A microservices application must be built according to a microservice design pattern, whether it is deployed in containers or not. It is possible to containerize an application as part of the process of converting it to a microservice, but that’s only one step among many.
When virtual machines came along, they made it possible to decouple applications from the systems they ran on. Docker containers take that idea several steps further—not just by being more lightweight, more portable, and faster to spin up than virtual machines, but also by offering scaling, composition, and management features that virtual machines can’t.
Docker tutorial
Ready to learn more? InfoWorld offers a series of tutorials covering Docker basics, Docker Compose, Docker swarm mode, Docker volumes, Docker networking, and Docker Hub. Docker itself provides a very basic Get Started With Docker tutorial. You might also want to try this basic tutorial from DZone. Once you get your footing, check out this extensive tutorial list to find other examples that will help you develop your Docker muscles.






